
Latest AI developments explained (OpenAI SORA, World models, Q*), Part I
How SORA works, how is it connected to world models? What about the Q* algorithm? How to make AI systems affordable for end users? Path towards personal LLM assistants, autonomous driving, etc.

Recently, stunning results of a new “text to video” generative AI model SORA have impressed not only the research community, but also the general public.

There are many examples of generated videos, and it is clear that the technology made significant progress from what has been available last year.
This is mainly thanks to a massive compute available and resources spent on training AI. As you can see, recent demand for GPUs to train models like SORA is much stronger than all the hype around bitcoin mining a few years back.

SORA was also trained on massive datasets some people are questioning. That is why OpenAI and other vendors of foundational AI models seek for quality datasets and data partnerships desperately.
But there is also massive human effort involved, maily:
Researching new algorithms
Data acquisition, curation, benchmarks
Foundational model training
Model alignment
Model productization (in progress for SORA)
The OpenAI team expanded from 45 members in 2017 to more than a thousand as of now. It is now just about research, but most importantly about making safe, reliable, scalable and affordable AI products and services. At the same time these modern teams need to be able to turn the latest research results and prototypes into scalable products very fast. And it can go wrong easily, as recent experience of Google Imagen 2 developers suggests.

The model alignment part is important and it is hard to find the right balance so the models are both useful for end users and not capable of generating content that can offend others.
What made SORA possible from the research perspective?
Let's discuss technologies behind SORA. Here is the list of most important stepping stones:
Self-supervised training
Understanding as compression
Neural autoencoders
Diffusion models
Vision transformers
Latent diffusion transformers
World models
Self-supervised training
For self-supervised methods, explicit human curated labels are not needed, therefore massive training data are often available. Most of the foundational AI models were trained on text, images, sound, videos or other data streams. Most usual learning scenarios are Masked modelling or Next tokens prediction where models just need to learn how to reconstruct or predict missing parts of data streams.
Understanding as compression
Information bottlenecks force machine learning models to compress and subsequently decompress data. During this process, one needs to discover correlations, symmetries and other patterns that some studies [1,2] argue is very close to actually understanding and reasoning about the data.
Neural autoencoders
Widespread neural autoencoders are typically realised by reducing and expanding dimensionality of input data in multiple steps, but it can be even much more trivial.

Problem of simple autoencoders is that they do not force similar inputs to be projected into similar parts of the compressed (latent) space. Variational autoencoders further enhance information bottleneck by gaussian noise in the latent space, enforcing better properties of the latent space.

Another successful approach to neural compression is Unet. This architecture enables models to reuse information lost during compression and can be easily extended to process 3D tensors, which is useful for video processing or spatio-temporal data modelling.

As you can see, Unets can be utilised in many ways, not only to predict next frames, but also to map different data modalities or ensemble several modalities into one prediction. Using this architecture, our Datalab won the weather forecasting Neurips 2022 challenge.
Diffusion models
Another technology, which became very popular recently, is to use noise as the information bottleneck.

Diffusion models use machine learning models to reconstruct images from noise, and for this, you need to learn to understand patterns in data again. SORA claims to use advanced denoising technique SDEdit.
Vision Transformers
Transformers revolutionised natural language understanding and generation. Now, they do the same with images and video.
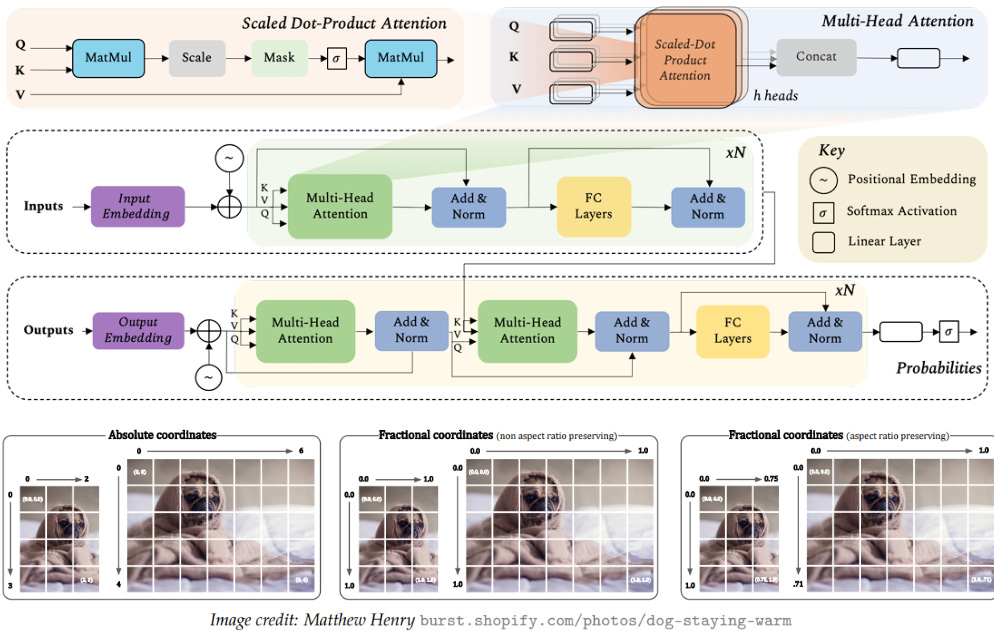
Spatio-temporal patches of video are fed to the transformer in order to model this data stream. This approach is however not so efficient and scalable to work directly with high resolution images and videos in 4k quality.
Latent diffusion transformers
Therefore, variational autoencoders can be used to encode a stream of patches into a latent space and transformers can then operate on encoded representations of these video fragments.
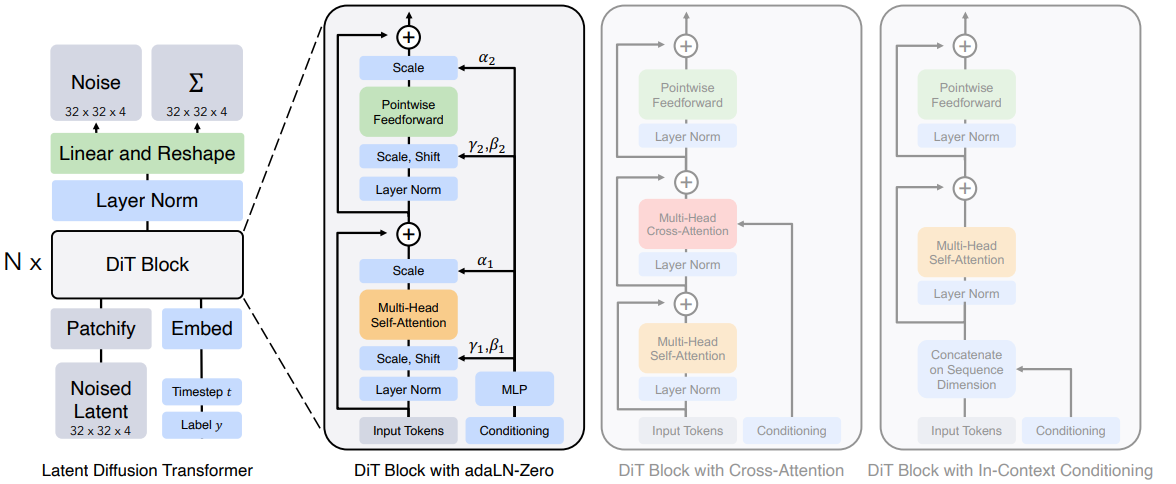
Modern diffusion models (Unets or transformers) are trained to predict noise so they can reconstruct the original signal by reducing predicted noise step by step during the denoising process. Again they operate in the latent space rather than original pixel space as regular vision transformers do.
World models
In reinforcement learning, agents observe the environment around them and predict how it will change based on their interaction with the environment.
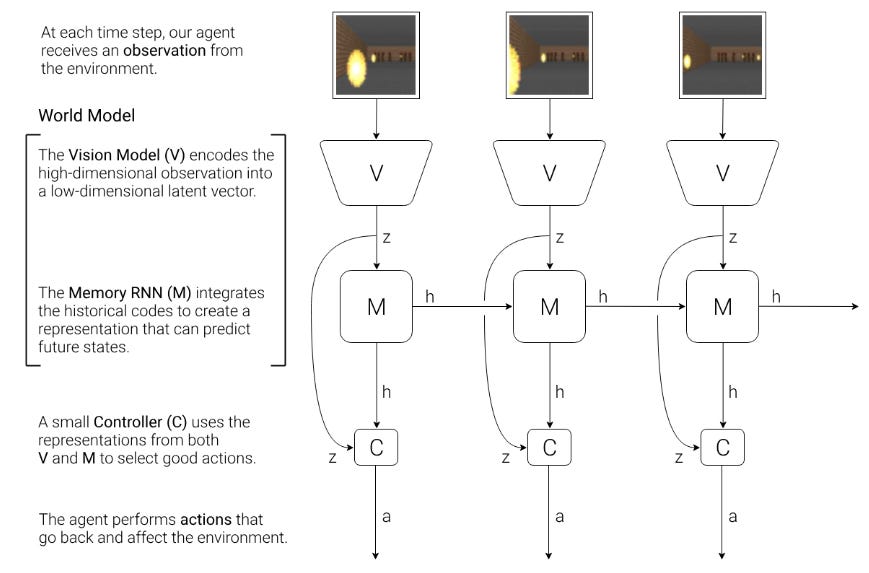
Modern world models also work with latent representations of the environment. That is why SORA video generation models are nicknamed as “world simulators”. Observing the world around us and being able to predict it is just the first step. Much more interesting is when you can actively influence how the environment will look in the future. Prompting SORA with natural language scripts to control how the environment develops is indeed much more powerful than just controlling an agent in the environment.
Part II of the post explains how these latest developments can be further enhanced by algorithms from the reinforcement learning field and speculate about secret Q* algorithm developed by OpenAI. Part III is devoted to real-world AI systems and how to make them affordable.